

From Pixels to Masterpieces: Generative AI Art
From Pixels to Masterpieces: Generative AI Art
Riding the Gen AI Renaissance Wave

Generative AI (“gen AI”) has rapidly ushered a new renaissance, with a sub-movement focused on text-to-image generation. The world was taken by a storm when Midjourney-generated images of the Pope in a Balenciaga puffer jacket went viral, rendering ‘fashionable Pope’ a meme and marvel.

Naturally, I wanted to get in on the action: create my own AI images, then experience for myself lessons to be applied as I look at potential gen AI investments. While I assume that much of what I say here will be obsolete in a number of weeks given how rapidly AI platforms are evolving, I intend this to be a layperson’s observations at this point in time, to be compared in the future. After experimenting for the last several weeks, here are my initial takeaways (more to be elaborated in future posts):
The platform you currently choose matters
Behind every stunning image is iteration
Vast horizontal use cases enable virality and rapid advancements
The platform you currently choose matters
I experimented with several gen AI image platforms—trying prompts myself, as well as observing others’ prompts and results on Discord. Some of these included Adobe Firefly, DALL-E, Leonardo, Midjourney, Stable Diffusion, and others. In my experience, Midjourney stood out as a leading platform: in summary, Midjourney was the most intuitive, precise, beautiful, and accurate.
For example, one of my first attempts: I conjured an image in my head of Pope Francis surfing The Great Wave off Kanagawa (神奈川沖浪裏 by Katsushika Hokusai). I typed the same prompt into four platforms and got wildly different results:

While none truly embodied what I was looking for, one far surpasses the others in quality: the pope’s face (or simply having a face), the wave’s shape and style, conceptual use of the boats/boatmen, etc.
Separately, I wanted to see Yoda at the disco. The prompt for all three were the same; I personally still liked Midjourney’s output the best for its realism and reflection of Yoda. Interestingly, the current consensus among many users is that “Midjourney has a tendency to ignore the requested style in favor of something ‘better looking’” and DALL-E delivers on a wider aperture of visual styles. This is evident in my output: DALL-E better stuck to my prompt (“dancing” and “colorful disco party”), but Midjourney took liberties to adjust for presumably better aesthetics.

Clearly, the platform you choose matters for getting the image quality you want. But it also matters because it’s a means of further aggregating economic advantage for an AI platform; the more people use a particular platform, the more feedback given, the more powerful the AI gets. Thus the arms race of AI. Each platform is doing a type of “reinforcement learning from human feedback” (RLHF) at scale. RLHF is a NLP technique that enables a model to apply human feedback and improve.
Currently, one of the best proxies for prompt-to-image quality is the image that a user decides to iterate, upscale, or download. For example, when you give Midjourney a prompt, it will generate four image options, after which you can choose to start all over with another prompt, or move forward on one of the four given images. Unlike many gen AI platforms, RLHF is naturally required and embedded in gen AI imaging products because users have incentive to “vote” on their preferred image.
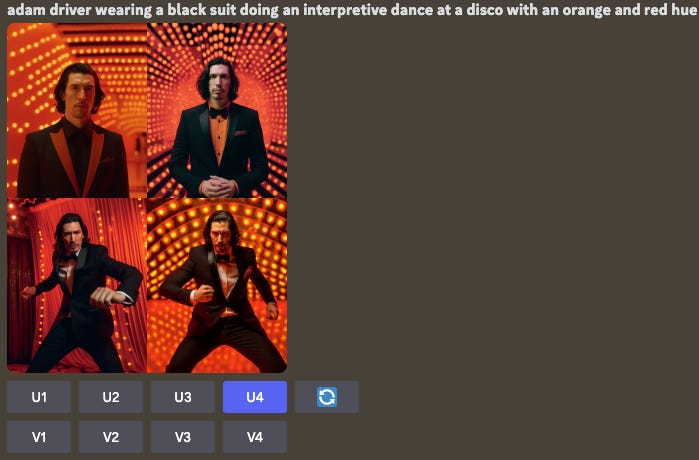

Behind every stunning image is iteration
In most instances, I realized it takes multiple attempts to generate the image I’m actually looking for, resulting from a combination of the current gen AI gap and me learning how to effectively prompt. Here are my top lessons from repeated experimentation:
Focus on a single person or product: All platforms struggled to produce 2+ people accurately. It would generally generate one person at the expense of another.


Don’t expect accurate hands or use of tools: As demonstrated by some of the Yoda photos above, machines currently frequently create deformed hands. Why? Biologically, a hand can have dozens of combinations of positions, representations, and sizing/ratios. AI still has a difficult time grasping (pun intended) how a hand works in connection with the human body.

Weightings can better help you get desired output: Using two colons and a number in a prompt indicates how much you want the AI to emphasize (or de-emphasize) a portion of the prompt. Without a prompt, an AI can risk mixing together particular thoughts that are meant to be separate. Colons indicate distinct ideas; numbers following colons indicate emphasis. If you want to de-emphasize something, you can use a negative number. For example, “::-2 abstract, grainy” will help prevent abstract, grainy imaging.
Notice the vast difference in accuracy when I applied a 5x [positive] weighting after “RBG” in order to accurately produce an image of RBG (versus a generic female) running a track race:
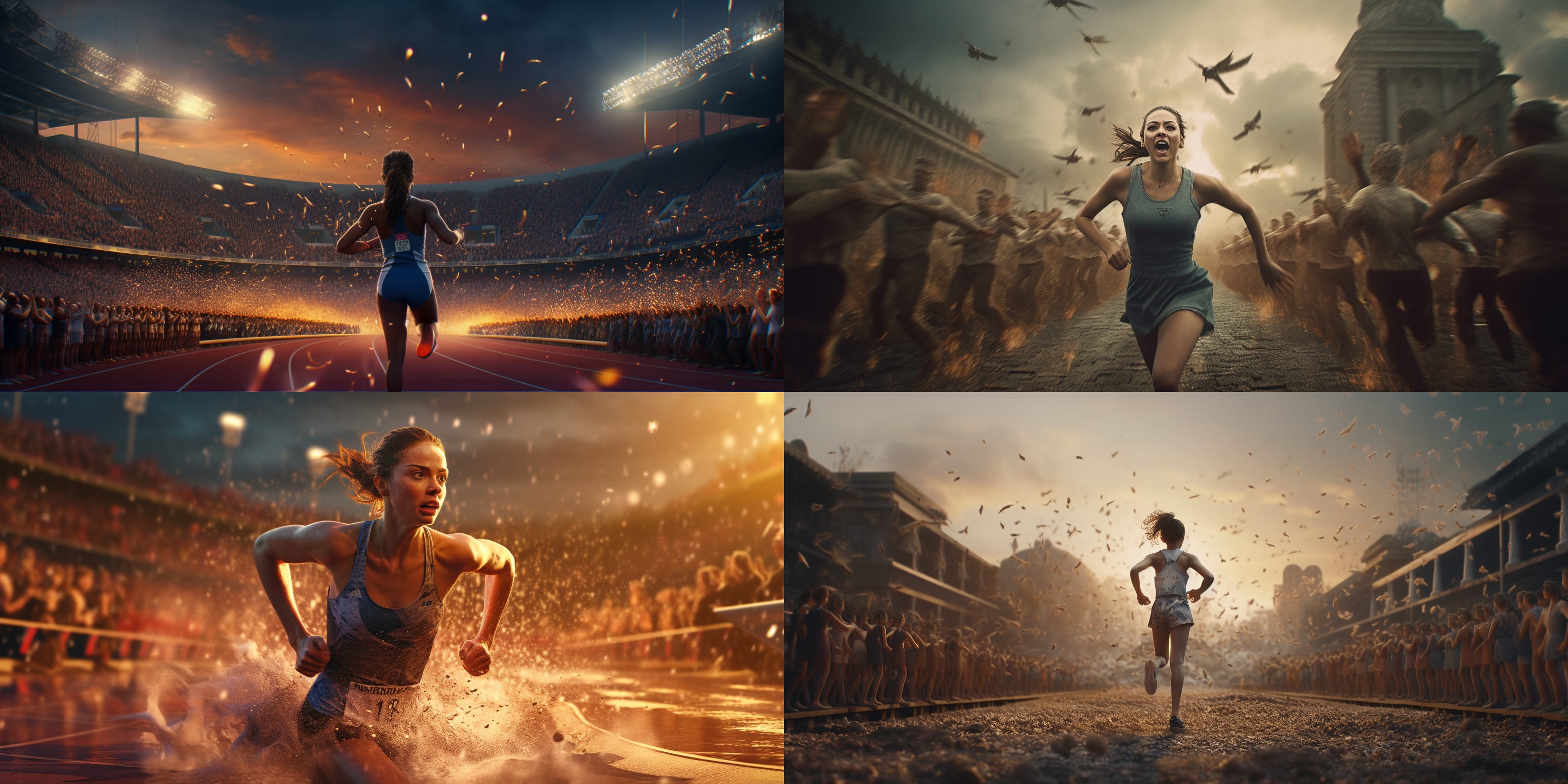

Parameters and styles go a long way: Similar to the concept of weightings, parameters can prompt the AI to bring in particular unique elements. My favorites include:


Vast horizontal use cases enable virality and rapid advancements
So far, the generative AI platforms that have advanced the farthest and fastest have been horizontal and open sourced, thrusting us in a period of insanely rapid innovation. In a recently leaked internal Google document, a Google employee revealed the company’s concern that it [and Big Tech] could lose the generative AI arms race to open source.
“Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months.”
-Leaked Google Document
How is this possible?
Barrier to entry is significantly lower to train and experiment models
AI improvement is predicated on mass, rapid, quality data—better enabled by broader community potential
Open source engenders tribal followings, enabling the long-tail underdogs to contribute and aggregate economic advantage against Big Tech
Many open source projects are, or start out free to users
Horizontal (as opposed to vertical-specific) use cases turn on large-scale creativity, attracting a wide aperture of personas ranging from consumers creating images for fun, to CPG design teams, to advertising/marketing teams, and more
In the last few months, we did diligence on a company where fantastic founders intended to create a gen AI solution for brands to produce product and marketing assets better, faster, and cheaper. Their intended use case was cutting out the need for camera equipment, location booking/travel, shoot time, models, and most editing. Similar to the concept of companies leveraging OpenAI’s plugins for corporate AI use cases, the founders intended to build on top of Stable Diffusion.
In a matter of weeks, the founders [and we as investors] were shocked to see how rapidly Stable Diffusion and alternatives evolved: users were generating incredibly accurate images in ways that were unseen directly prior. How? The founders came to a similar conclusion: open source projects would become dreadfully difficult to contend with. Their hypothesis warranted a pivot.
“Holding on to a competitive advantage in technology becomes even harder now that cutting edge research in LLMs is affordable. We can try to hold tightly to our secrets while outside innovation dilutes their value, or we can try to learn from each other… People will not pay for a restricted model when free, unrestricted alternatives are comparable in quality.”
-Leaked Google Document